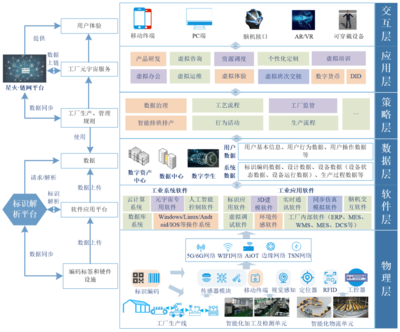
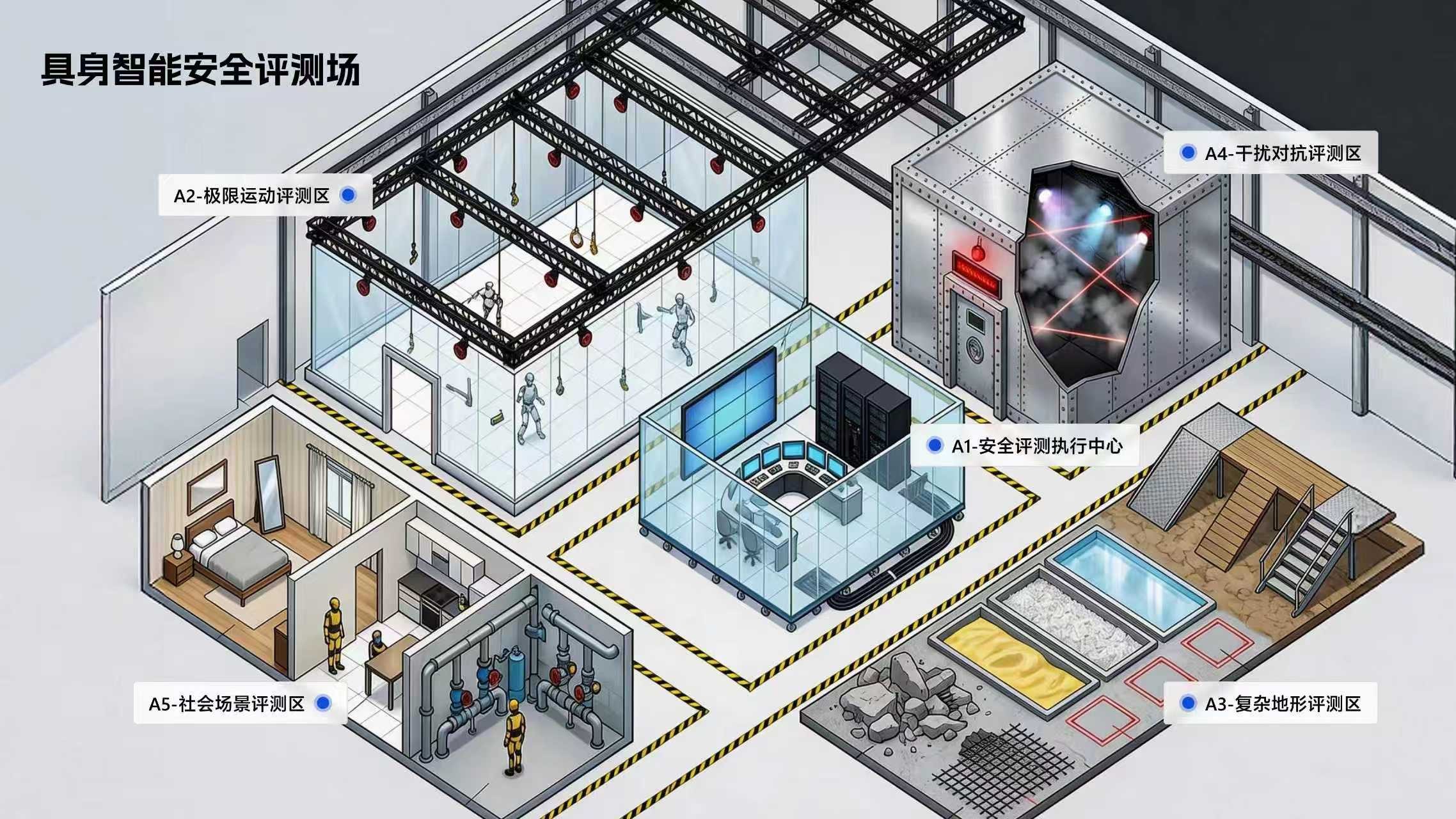
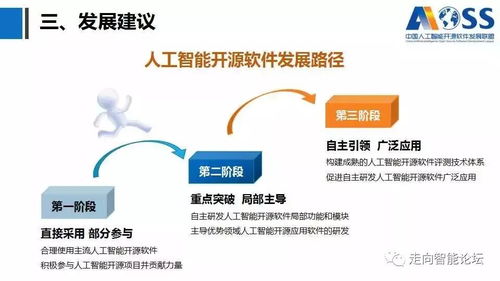
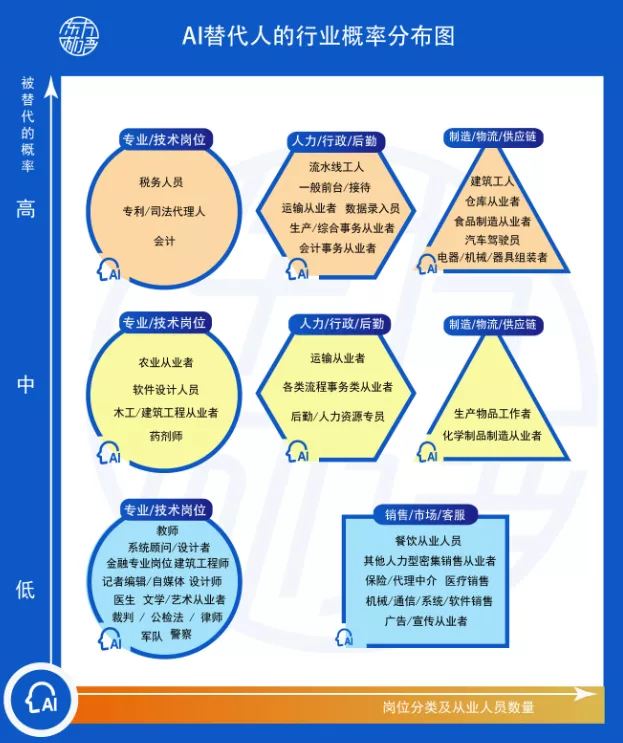
在人工智能的璀璨星河中,大模型、深度学习、生成式AI等技术术语占据了舞台的中心。在这光鲜的技术表象之下,有一条看不见却至关重要的基石在默默支撑着一切:数据。事实上,人工智能实践的每一步都在强调一个不争的真谛:即使是最顶尖的算法,其所有“智能”的来源也离不开数据的清洗、治理和建模。从人工智能基础软件的开发底层逻辑看,这不仅是一个工具栈的问题,更是一场对数据价值的系统性重塑。\n\n### 一、数据基础设施是第一生产力的实现路径\n\n很多人曾困在误区中:是否只要引入了AI模型,企业业务就会立刻智能?答案是否定的。人工智能的所谓“高科技感”从来不是魔幻变形,而是建立在高德的数据成熟度(Data Maturity)之上。如果原始工序还未实现数据治理、语料采集的过程不具多样性,或者人工标注(ground truth)噪音过大,那么多GPU堆模型的逻辑就会阻塞在初始阶段。缺乏高质量的行业视角数据库,公司就像要在农田之上放高楼,无疑适得其反。从这点看,基础软件投入成本的最大边际汇聚便回到了对如何搭建容纳清洗规则下的适配材料结构的问题。这种观点解释第一性原理:data决定了智能的上边界限度,模型运作的唯一任务只是使现实的分布趋于特征,这也成为解决方案团队开发工业情境时判断的关键实践准备。“脏数据从来无法构建稳健连接链路\
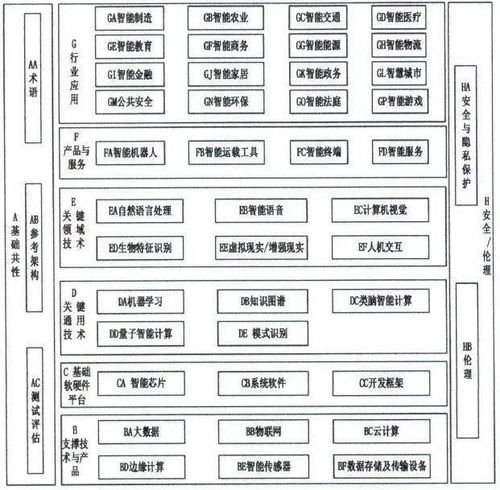
数据为基 人工智能基础软件开发的根脉与蓝图
如若转载,请注明出处:http://www.htylte.com/product/28.html
更新时间:2026-06-18 08:07:18